


The Beginner's Guide to Databases
The Beginner's Guide to Databases
There are 300+ databases; what do they all do?

There are at least 300+ databases out there, and they all do something slightly different. From Postgres to Elastic to Cassandra, there are virtually unlimited ways to store and query your data; and most companies will use several of them in tandem. So when your engineering lead tells you that the project is going to take an extra two weeks because they need to create a new data store for log analysis, what exactly is going on?
Allow me, for a moment, a metaphor.
I’ve gotten into baking recently, and choosing which type of flour to use has been an unexpectedly important piece of the equation. Each flour type has a different protein content; more protein means more gluten, which (generally) means a thicker bread. For pastries you use flour that has less protein, since you want them to be light and flaky. Flour for pizza dough should have more protein since you want it to be chewy. And then you’ve got all purpose flour, which is sort of in the middle, and you can use it for everything, although the results won’t be as good as if you picked the perfect flour for the job.
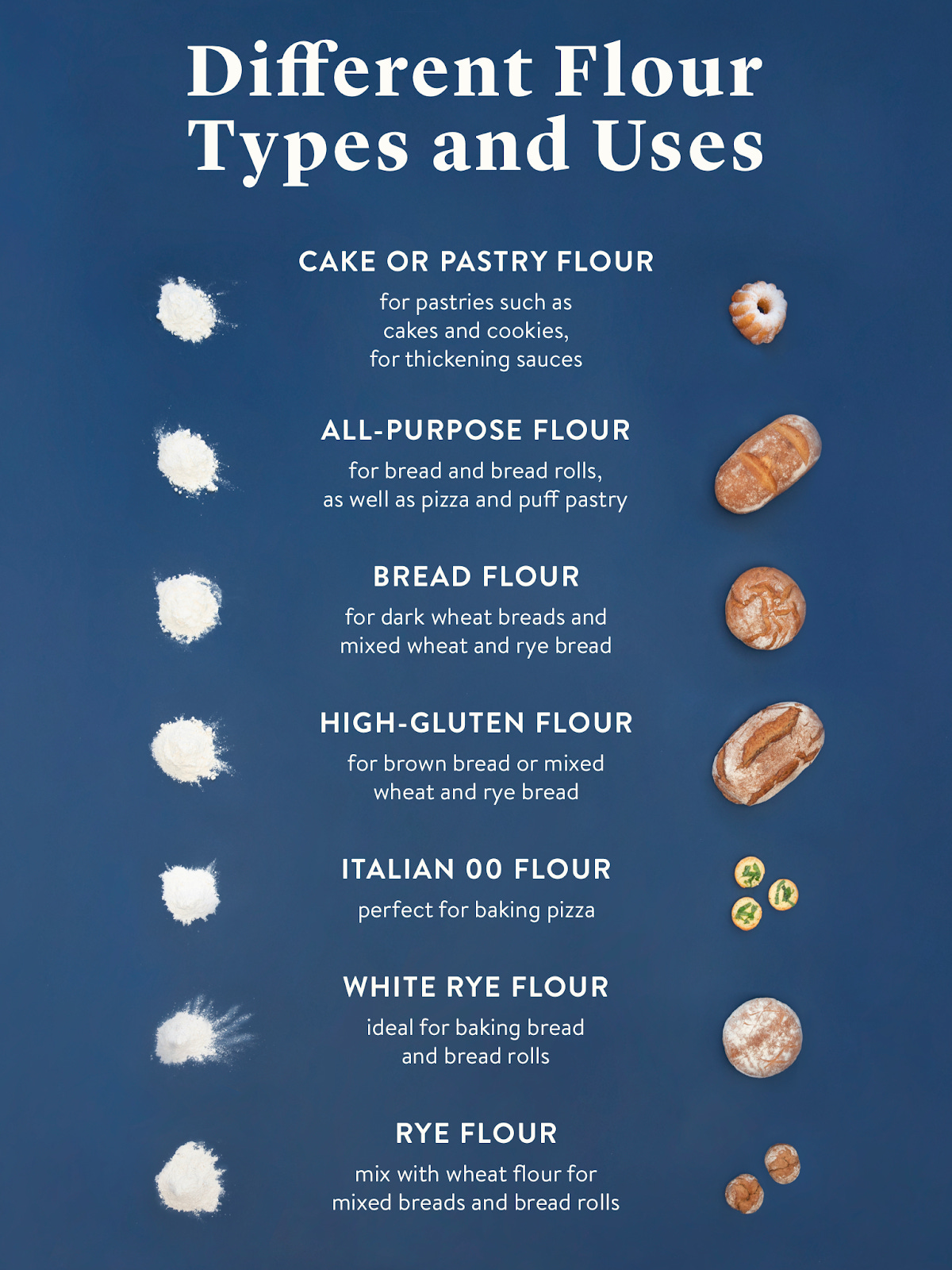
Databases are basically the same thing. Each one is designed with a specific set of constraints in mind. You can use any of them for anything – and some are more general purpose than others – but finding the right database for your use case is important if you want the best possible bread outcome.
To understand what a database does and why you’d use it, ask 2 questions:
What does the data look like?
Technically, you can store any piece of data in any database. Postgres is relational, but supports big blobs of text. Nothing is stopping you from storing your user data in Elastic. Nevertheless, many databases are designed with specific types or shapes of data in mind. A graph database is made for modeling data made of up interconnected nodes. Snowflake is made for storing large analytical data sets. Each one has a use case it was perfected for.
The real reason why the data type matters is not the actual storage of the data – remember, you can store anything anywhere – it’s the insertion and retrieval of the data. Speaking of which…
What do you need to do with it?
Different types of data – and even similar types of data for different use cases – get used in different ways. A good example is thinking about transactional, production databases vs. analytical databases:
OLTP (online transactional processing) – these are the databases that you use for the core data in your application, think your user data. Data is being read and inserted constantly. Queries are usually small and quick. Data integrity is key.
OLAP (online analytical processing) – these are the databases that you use for analytics and data science, think Snowflake etc. Data is being read and inserted sporadically. Queries are usually large and complex.
The fact that users of the database need to do different things with the data inside of it necessitates storing said data differently.
OLTP vs. OLAP is one example, but there are many different ways to break down those use cases. Some databases have special UIs on top for analysis (like Kibana and Elastic). Others are built for massive scale from the start. Some are made to handle many different situations decently well. No matter what database you’re dealing with, thinking about what kind of data it stores and how you need to use that data is the key to understanding each.
3 major categories of databases and what they do
Crude as it may be, I find it useful to think of 3 major categories of databases. Some databases can overlap and cross categories. For example, there are NoSQL databases built for powering your app, but there are also NoSQL databases meant for in-memory stuff (e.g. Redis is technically NoSQL). Here are the major ones:
Databases that power a user-facing app – production databases that store the data you need for your app to run.
Databases that power analytics – databases for analysis, machine learning, and anything a data team does.
Databases that power operations – databases for monitoring, logs, security, and any internal processes that enable the above.
Let’s run through each category and cover a few examples for each.

Databases that power a user-facing app
Databases that power a user-facing app – often referred to as production databases or production data stores – are where developers store and query whatever data their app needs to run. Any “data” you’re seeing on your screen sits here.
If you’re Twitter: tweets, user profiles, trending topics, DMs
If you’re Gmail: emails, settings, spam filters
If you’re Amazon: orders, users, credit cards
Production databases are built to support small and quick queries. The most important thing is data integrity and reliability – you don’t want to lose an order or a credit card.
User-facing DBs / Relational Databases
Relational databases are the database OGs. They’ve been around for pretty much as long as databases have been around, and are the default choice today for storing the basic data your application needs to run. Data is stored in a very structured format with rigid definitions of tables, columns, and how tables relate to each other; that way, queries can run quickly and reliably.
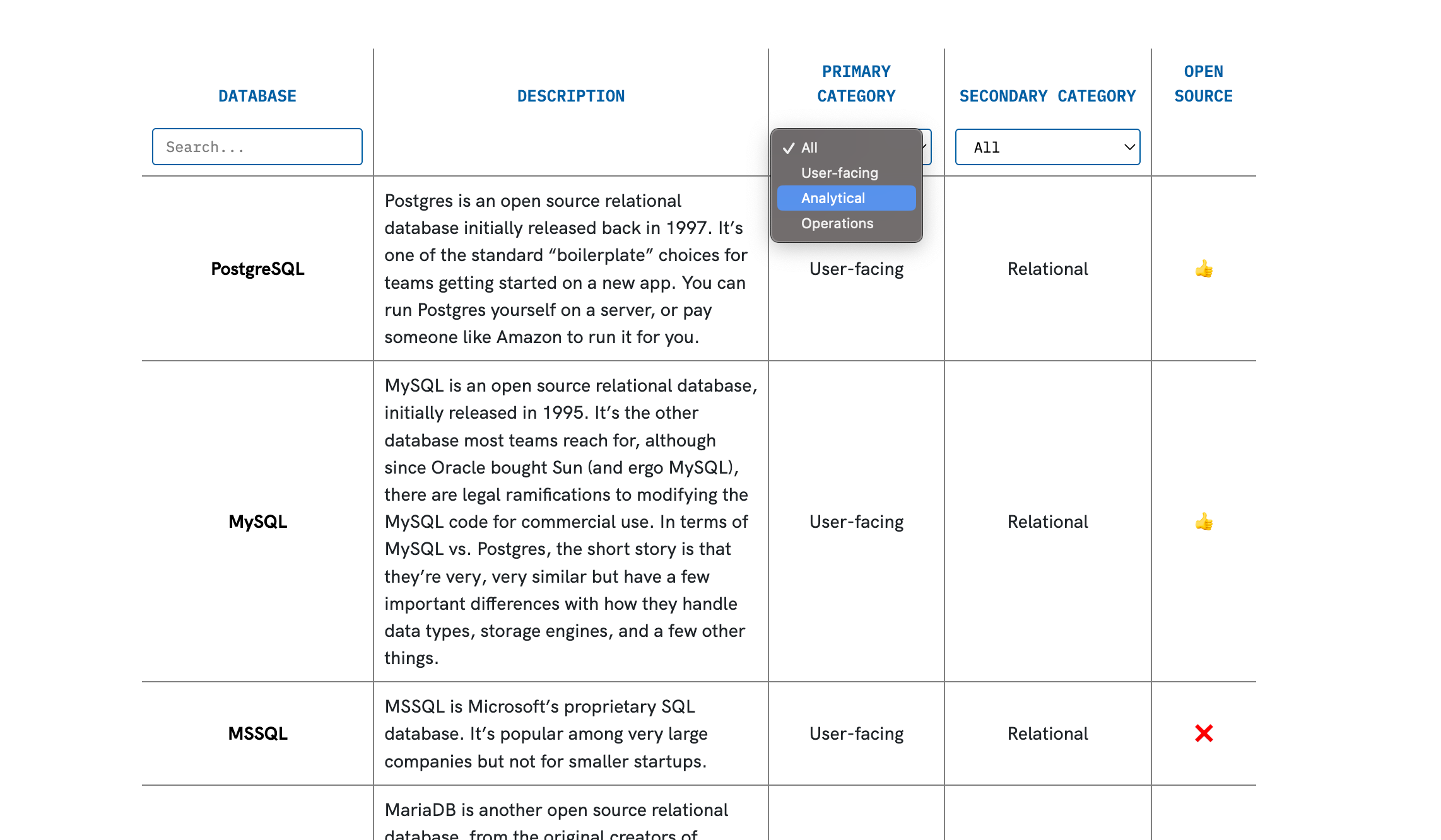
Postgres is an open source relational database initially released back in 1997. It’s one of the standard “boilerplate” choices for teams getting started on a new app. You can run Postgres yourself on a server, or pay someone like Amazon to run it for you.
MySQL is also an open source relational database, initially released in 1995. It’s the other database most teams reach for, although since Oracle bought Sun (and ergo MySQL), there are legal ramifications to modifying the MySQL code for commercial use. In terms of MySQL vs. Postgres, the short story is that they’re very, very similar but have a few important differences with how they handle data types, storage engines, and a few other things.
MSSQL is Microsoft’s proprietary SQL database. It’s popular among very large companies but not for smaller startups.
Oracle was the first commercial relational database ever. Today it’s got the reputation of being the slowest moving company in California, but nevertheless powers the apps of tons and tons of Fortune 50 companies. Like MSSQL, this is a database for massive organizations and not startups.
MariaDB is another open source relational database, from the original creators of MySQL. They (in a somewhat cheeky fashion) seem to be pretty pissed about Oracle limiting contributions to MySQL, so they focus on how open the community is and how the software will never require a license.
SQLite is a software library that lets you run a small database inside of your application. It’s used in one way or another in tons and tons of apps, usually as an intermediate database as opposed to a core production store. The website says it’s on every single Android, iPhone, etc.
User-facing DBs / NoSQL Databases
NoSQL databases remove the structure and rigidity from relational databases, and let you just dump data in there and worry about how it looks later. There are NoSQL databases for all different categories of database (analytics, operational) but these here are for production, user-facing use.
MongoDB popularized the NoSQL moniker and is the default choice if you’re looking for a NoSQL database to power your app. Their cloud product, Atlas, is the AWS RDS equivalent for basic NoSQL.
Cassandra is a NoSQL database built for really big companies who need to store lots of data and retrieve it fast. Unlike MongoDB, which is built as a document database, Cassandra is oriented more around a columnar setup, which means data is stored in entire columns (like Snowflake, actually). Using Cassandra feels a lot more like using a relational database. Thank you to
from the for pointing out that Cassandra is actually technically not a columnar data store, but instead implements the concept of a wide column family, which is slightly different.DynamoDB is AWS’s proprietary NoSQL database.
Firebase is a series of tools (acquired by Google back in the day) for building apps, targeted at smaller teams and focusing on simplicity. Their database is called Firestore and it’s a really popular option for a quick, just-get-me-started kind of DB.
User-facing DBs / Graph Databases
Every company’s data is different, and for some it makes the most sense to model things as a sort of graph of interconnected nodes. Facebook famously runs their social graph on an in house graph database called Tao. The use cases for graph DBs are mostly user-facing, but they’re sometimes useful for analytical purposes too.
Neo4J is the most popular graph database. It’s open source but if you’re going to scale it up, you’ll need to talk to them about their enterprise license. Data in Neo4J is represented as nodes, and nodes can be connected to each other in different ways. Cyper is the name of their SQL-esque language for querying the graph.
Databases that power analytics
What a data team needs from their database is very different from developers working on an app. For data science and analytics work, the data you store is often redundant, there’s tons of it, and your queries join data from multiple tables at once. Data usually gets queried by someone sitting at a computer doing research, or a system building a pipeline, and gets inserted at regular intervals (twice a day, something like that).
Analytical DBs / Data Warehouses
Data warehouses are (usually) relational databases for storing analytical data, like what your users have been doing, revenue by month, things like that. They’re optimized for big, long, multi-table queries. They’re usually relational databases in nature, although the implementation details can vary.
Snowflake is a cloud data warehouse for analytics. It’s columnar, which means that data is stored (under the hood) in entire columns instead of rows; this makes large analytical queries faster, so it’s a common choice for how to build analytical DBs.
BigQuery is also a cloud data warehouse for analytics. It’s very similar to Snowflake.
Redshift is also a cloud data warehouse for analytics. It’s very similar to Snowflake and BigQuery.
Clickhouse is an open source (!) data warehouse for analytics. It was originally developed at Yandex, and is getting more popular.
🤔 Why can’t I use Postgres as a data warehouse?
You can, people did for a long time, and some still do. But modern cloud data warehouses are just waaaaay faster for large queries on meaningful quantities of data. This is the thing about databases: you can use anything for anything, but there comes a point where you need a specialized tool for the job.
Analytical DBs / Data Lakes
Data Lakes are basically giant data safes. You throw whatever you want in there – structured, unstructured, big, small, organized, disorganized, whatever – and then worry about structure when it’s time to get the data out. Contrast that with a data warehouse, which like a relational database, has rigid structure around tables, columns, and data types.
S3 is AWS’s object storage solution – usually used for storing things like images and videos for applications – but is also commonly used as a data lake. You can’t “query” S3 in the way that you can a database, so you need to use a layer on top (like AWS’s Lake Formation) to intermediate.
Databricks, a company that I wrote about back in the day, sells a product they call “the lakehouse platform.” Under several layers of caked marketing makeup, it’s an open source data lake and storage layer built to resemble a sort of data warehouse; they’re trying to blur the distinction between the two.
Though it’s unlikely you’ll see it in production today, HDFS was a highly popular way to build a data lake before the cloud data warehouse era. It’s powered by Hadoop, one of the original frameworks for performing distributed computations on large groups of data. It was/is notorious for being very, very hard to set up and run.
Analytical DBs / GIS Databases
This is a bit of a niche one, but worth mentioning: there’s a class of databases (or in some cases, database extensions) that are purpose built for working with geographical data. GIS stands for Geographic Information System. In terms of the actual data being stored here, it can be anything from points and lines to complex 3D data; structures that don’t map (no pun intended) well to traditional database schemas.
PostGIS is a PostgreSQL extension for storing and working with geographical data. It’s a combination of features for storage, analysis (special geographical functions like intersections, measuring distances, etc.), and other miscellaneous stuff like geocoding.
Kinetica is an enterprise-focused database for storing geospatial and time series data.
Oracle Spatial Database is also an enterprise-focused database for storing geospatial data, from our friends at big red.
(Thank you to Ajay Anand for all of this information!)
Databases that power operations
This is the category you’ll probably encounter least if you’re not an engineer. The 3rd category of databases covers data stores that developers use to power internal operations: monitoring application performance, storing logs and security information, improving application speed, or even intermediate layers between other databases.
Operational DBs / Key Value Stores
While pretty much all of the databases we’ve covered so far store permanent data – saved on a harddrive – there’s a class of databases that only keeps data in memory. They’re meant for ephemeral data that you need to store and use quickly, but you don’t mind if it disappears down the road. These databases are called key value stores (or KV stores) because the way they store data is like a dictionary, where each entry has a key.
Redis is the OG key value store. It’s an in memory database that teams use for a bunch of different stuff: building caches, managing authentication sessions, chat and messaging, and any other use cases that prioritize real time, very quick data retrieval. Redis is open source but you can also pay them to host it for you.
SingleStore (FKA MemSQL) is an in memory database like Redis, more focused on general purpose kinds of workloads than typical in memory database use cases.
Operational DBs / Time Series Databases
Time series databases are DBs built specifically for storing data on some sort of time frame: daily financial data, second-by-second sensor readings, hour-by-hour health checks on your servers, anything like that.
Timescale is an extension to Postgres, sold as an independent cloud hosted database. It takes everyone’s favorite relational database and adds special time-series specific functionality like automatic partitioning and query optimizations.
Prometheus is an open source time series database with built in alerting and visualization.
InfluxDB is also an open source time series database.
Operational DBs / Logs and Search Databases
Elastic is a NoSQL database built for storing and searching through logs, or very granular records of server performance, API requests, and internal stuff like that. Elasticsearch is commonly used with Kibana, its sister data visualization tool.
Solr is also a NoSQL database built for storing and searching through logs.
The Database Database
For convenience and quick reference, I’ve organized the above into an easy to use table interface that you can find here.
If you found this post useful, feel free to share!
“I heard you like databases, so I added a database of databases on my post about databases” -Justin, probably
Super interesting! Thank you