


What are microservices?
What are microservices?
What is this? An architecture for ants?

Elon Musk set engineering Twitter ablaze (again) recently with his comment on Twitter’s backend problems:

So what exactly is a microservice?
The TL;DR
Microservices (all hype aside) are a way of building your application as a series of small, interacting services instead of one giant bundle of code.
All applications are made up of a bunch of interacting services: databases, API endpoints, the frontend, etc.
Typically, these services all run together, on the same infrastructure, in the same codebase
In a microservices based architecture, services are separated into smaller units that run independently
Microservices help you scale more effectively and avoid downtime, but come with steep complexity costs
A good percentage of bigger tech companies (think Google, Pinterest, Uber, etc.) have built their apps as a series of microservices, and it’s becoming a more popular design pattern for smaller teams as well. Buckle up, we’re bringing memes back.
What’s a service?
Before we can talk about “micro” or other adjectives describing services, we need to define what a “service” actually is; for me at least, it wasn’t a term I had heard engineers use very often.
A service refers to any piece of an application that functions independently. Services usually refer to things on the backend, but can also refer to frontends. Let’s imagine you open up Uber on your phone and request a ride. A lot of things are happening behind the scenes:
Finding the drivers that are closest to you
Ensuring those drivers are vacant or finishing up a trip
Matching you with the optimal driver
Deciding what price to show you
Deciding what price to show the driver
Creating an ideal route for the driver to navigate to you
…
These could all be described as services. This is of course illustrative – I’m sure we’re missing plenty, Uber’s backend is hella complex.
A heuristic – one that’s often right, but not entirely true – is to think about services in terms of API endpoints. Each one of these tasks described above may have its own endpoint:
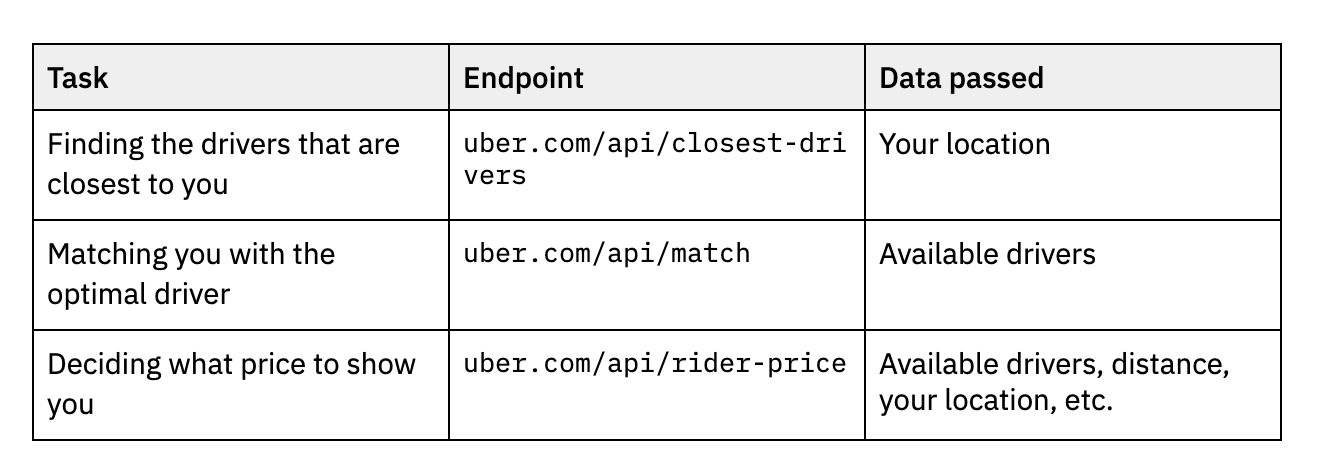
In practice some of these will probably not be their own endpoints, or some will be their own endpoints but mostly call on other endpoints. The price endpoint might be in front of some giant machine learning model, while the match endpoint could be a simple algorithm or some if statements. The closest drivers endpoint might just be reading basic data from a database. We can’t really know, and it doesn’t matter; what does matter is each one of these “things” is its own service and has its own role in the backend.
🚨 Confusion Alert 🚨
API endpoints and the logic behind them are not the only things that can be considered services. Your application’s frontend (HTML, CSS, JavaScript) can run independently as well, and may even be able to be broken down into its own set of microservices. Today’s databases are often replicated across multiple servers for high availability, too.
🚨 Confusion Alert 🚨
So how do these things actually get built in practice?
Beware the monolith
The historically dominant way of building applications – groups of these interacting services – is what’s called a monolith. This rather harrowing name really just refers to the idea of having all of your services, database, frontend, etc. deployed on the same set of infrastructure in one big group of code files.

To put this into practice, let’s get back to our Uber example. If Uber had architected its systems monolithically, all of those API endpoints would be doing their things on the same server, or they’d be replicated equally across identical sets of servers. So even though the endpoints themselves do different things, they’re all sitting right next to each other, figuratively. They might even be on the same server as the database(s) and the frontend.
Monolithic development is easy and makes a lot of sense. You don’t need to think too much about where your code goes, and for most applications, this won’t impact performance too much. But as companies like Uber got larger and dealt with more and more volume (literally, number of people making requests to those endpoints), they started to notice a few issues with the monolith philosophy:
Scale – every service gets used differently, some more popular than others. If they’re all on the same infrastructure, it’s impossible to scale one up without scaling all of the others up.
Uptime – if one service has an issue and stalls / brings down your server, all of the other ones are fucked too.
Specialized Infrastructure – for some use cases like machine learning or video processing, specialized infrastructure like GPUs are critical; you cannot make use of them in a monolithic architecture.
Developer experience – with all services on the same box, developers who want to make a change to just one service need to redeploy and retest the entire server / application. Plus, all services need to be in the same programming language.
So though monoliths are much easier to build and get started on, these companies found a smarter way to build all of their services together.
Honey, I’ve shrunk the code
In a microservices based architecture, services are separated into independently operating pieces. Each service can be deployed on its own without depending on any of the other ones, and communicates via some sort of API endpoint. This diagram from Martin Fowler’s excellent in depth piece explains things well:
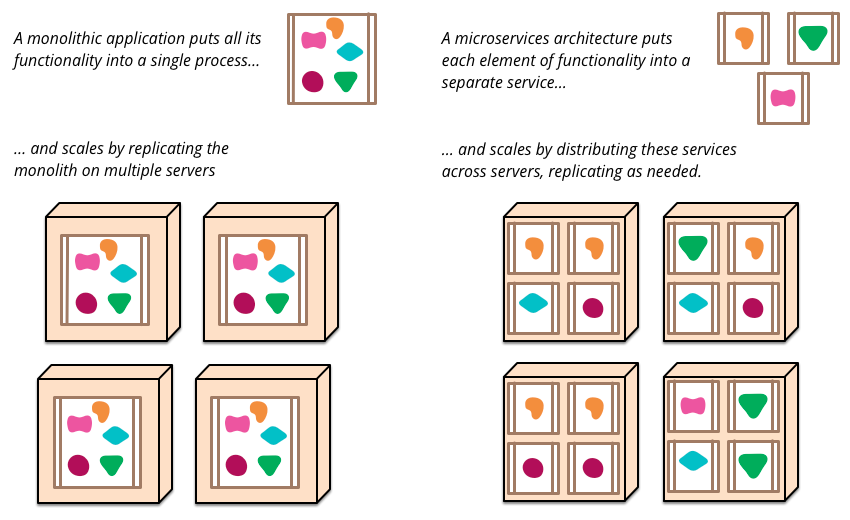
Not every service gets deployed on its own dedicated server (although this is probably happening at Uber). What makes it a microservice is the fact that it can run independently, and interfaces with the rest of the codebase via an API endpoint, as opposed to a function call or importing a library.
🔍 Deeper Look 🔍
I highly recommend reading Fowler’s post if you’re interested in a more in depth technical definition on what might distinguish a microservice from a regular old service. In short, a service needs to be independently deployable and communicate via a request/response model.
🔍 Deeper Look 🔍
When you build your application and backend as a set of interacting microservices, you solve the problems that teams run into with monoliths:
Scale – you can independently scale any service by putting it on a bigger server, several smaller servers, etc.
Uptime – independently deployed services don’t take other services down when they fail (you will still need to fix them though, and handle what other services do when any of their friends have failed).
Specialized Infrastructure – you can deploy an ML service on a server with some big GPUs.
Developer experience – each service can be built in whatever programming language the team who owns it wants, and be edited and improved independently.
A useful (bit admittedly not perfect) way to think about the difference between a monolithic architecture and a microservices-based one is to think about shipping things in separate containers. Imagine you’re Amazon, and you need to get a bunch of stuff across the ocean to your customers. You’ve got quite the variety of items that need to get moved:
Matches
Cashmere Sweaters
Rice
Food Processors
The easiest way to get this done is to put everything in one big container, plop it on a boat, and be done with it. And that might work at small volumes, but it’s terribly inefficient, because all of these goods require very different types of packaging, transport, speed, and care:
Matches: very flammable
Cashmere Sweaters: very light, sensitive to water
Rice: very heavy, somewhat perishable
Food Processors: very heavy, sensitive to water, fragile
Separating these items into their own containers will allow you to package, care for, and ship them in independent ways. And the same thing pretty much applies to software services.
Microservices are not a silver bullet, plus ecosystem considerations
While what we’ve described above sounds like an ideal setup (separate your services!), there’s a big, big cost to a microservices architecture: complexity. Creating and maintaining a network of interacting services is a pain in the ass, and for smaller companies is probably more headache than it’s worth.
With all of your services separated into independently deployed “things” you’ve now got to deal with new problems:
How do my services authenticate with each other?
How do my services know each other exist?
With different teams working on each service, how do we make sure there are SLAs (agreements) on what each service does? Documentation?
What happens if a service is written in Go, but your team only knows JavaScript?
Or in other words, this meme:

So in summary, like every architectural decision in software, this one comes with clear tradeoffs, and there’s no right or wrong answer. I’ve worked at companies that have implemented monoliths and ones that have done microservices, and both have figured out something that works for their unique constraints.
A closing note: with problems come solutions, and there’s a spate of interesting new projects and tools aimed at solving the problems that microservice sprawl creates. If you’ve heard of a service mesh, it’s a concept aimed at solving the issue of how services are aware of, authenticate, and interact with each other. Tools like Optic (disclosure: I’m a small investor) help teams document and test their API endpoints. In other words, some of these problems are being worked on.
What did you think of this post?
I think I had all of this with DEC's ACMS architecture back in the 90's without most of the cons you listed.
Aren’t micro services cheaper to run since cloud costs skyrocket for larger instances?